How to use machine learning (if you can’t code) to help your keyword research
I have previously written about why keyword research isn’t dead. A key theme I continually make is that keyword categorization is incredibly important in order to be useful so that you can optimize towards topics and clusters rather than individual keywords.
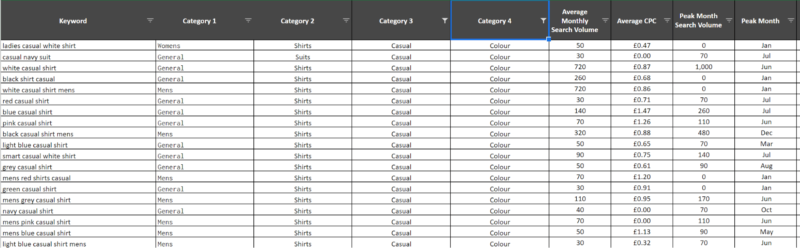
My keyword research documents often exceed 20k-50k keywords which are normally broken into two, three or sometimes more categories reflective of the site taxonomy in question.
As you can see, I have categorized the keywords into 4, filterable, columns allowing you to select a certain “topic” and view the collective search volume for a cohort of keywords. What you can’t see is that there are over 8k keywords.