

My keyword research documents often exceed 20k-50k keywords which are normally broken into two, three or sometimes more categories reflective of the site taxonomy in question.

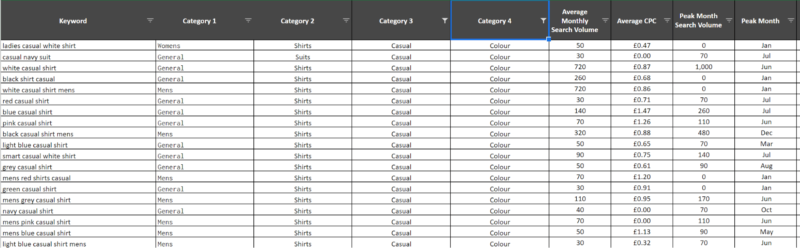
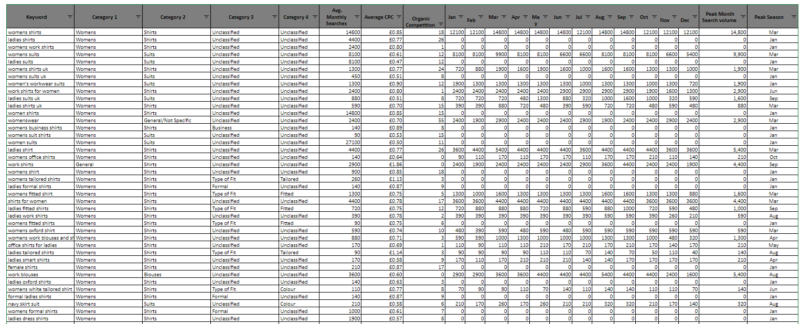
As you can see, I have categorized the keywords into 4, filterable, columns allowing you to select a certain “topic” and view the collective search volume for a cohort of keywords. What you can’t see is that there are over 8k keywords.
A few years ago I used to categorize this fairly manually, using some simple formulas where I could. Took ages. So I made a keyword categorization tool to help me. It’s built using php and still pretty rudimentary but has sped the time I am able to do keyword research and categorize it from a couple of days to 12-15 hours depending on how many keywords there are.
I’m a sucker for a trend. So the minute all the SEOs started shouting about how great Python is, of course I am on the bandwagon. My goal is to streamline the keyword research process even further and I’m loving learning such an adaptable language. But then I came across this video by David Sottimano where he introduced BigML into my life. Imagine an online “drag and drop” machine learning service; a system literally anyone can use. This is BigML.
I am still pursuing my ultimate goal of mastering Python, but in the meantime, BigML has provided me with some very interesting insights that have already sped up my keyword categorization. The aim of this article is to give you some ideas about leveraging (free) technologies already out there to work smarter.
A quick note before we delve in, BigML is a freemium tool. There is a monthly fee if you want to crunch a lot of data or want added features (like more than one person on the account at one time). However, to achieve the results in this article, the free tier will be more than enough. In fact, unless you’re a serious data scientist and need to analyze a LOT of variables, the free tier will always be enough for you.
Step 1 – Getting the training data
For this example, we’ll pretend we’re doing keyword research for River Island – a large clothing retailer in the UK for all my friends across the pond. (If you’re reading this and work for River Island, I will not be doing full keyword research.)
If we look at River Island’s site taxonomy we see the following:

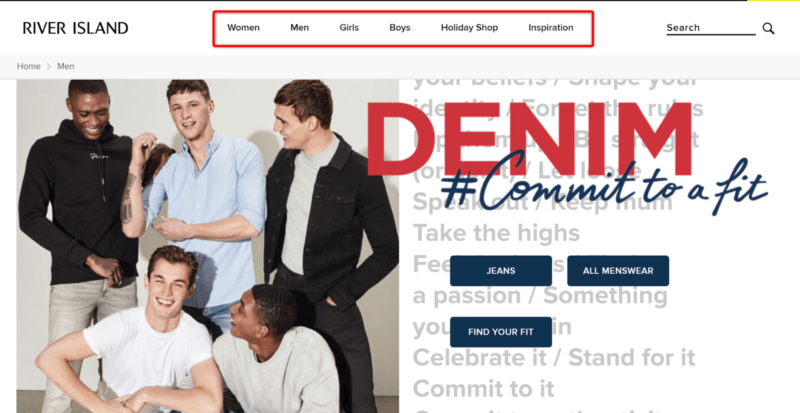
For the purpose of this guide, we’ll just do keyword research for men and focus on these few product items:

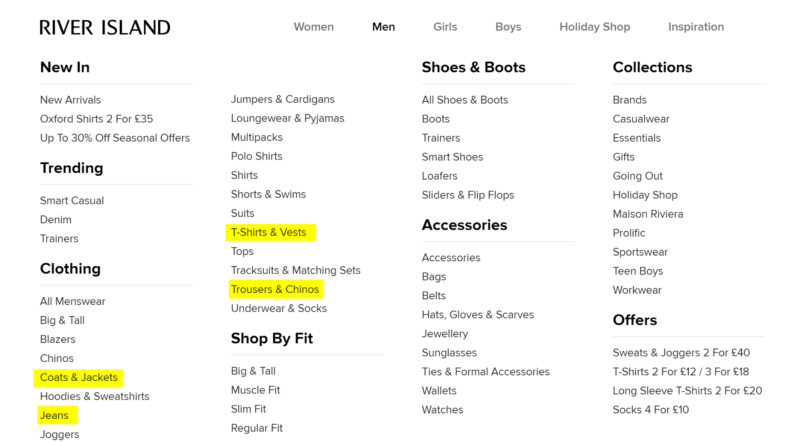
Let’s say, hypothetically, I want to group my keywords into the following categories and subcategories:
Tops > Coats and Jackets
> T-Shirts and vests
Bottoms > Jeans
> Trousers and Chinos
We’ll do the “Bottoms” first.
Grab the “jeans” URL for River Island and plug it into SEMRush:


Filter by the top 20 keywords and export:

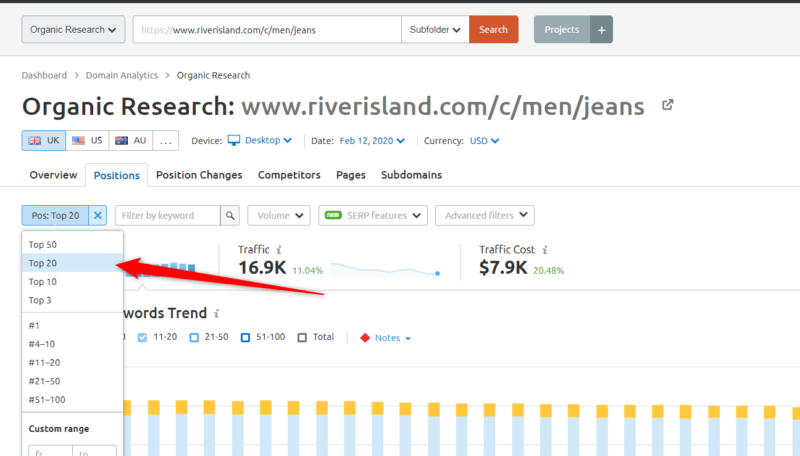
I’ve chosen the top 20 because often, beyond that, you start to rank for some irrelevant and, sometimes, quite odd keywords. Yes, River Island ranks number 58 for this term:

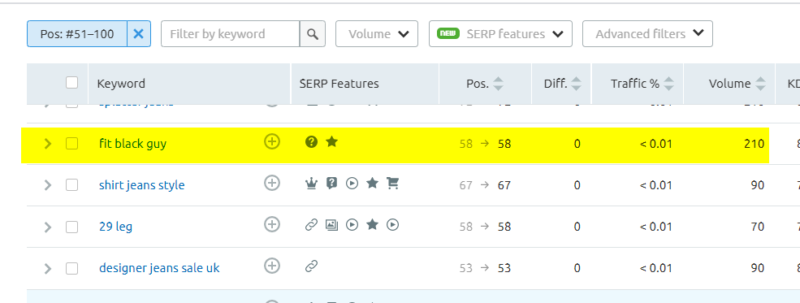
We don’t want these terms affecting our training model.
For “jeans”, when we filter for keywords in positions 1-20 and export, we get 900 odd keywords. Drop them into a spreadsheet and add the headings “category 1” and “category 2”. You’ll then drop “bottoms” into category 1 and “jeans” into category 2 and fill down:

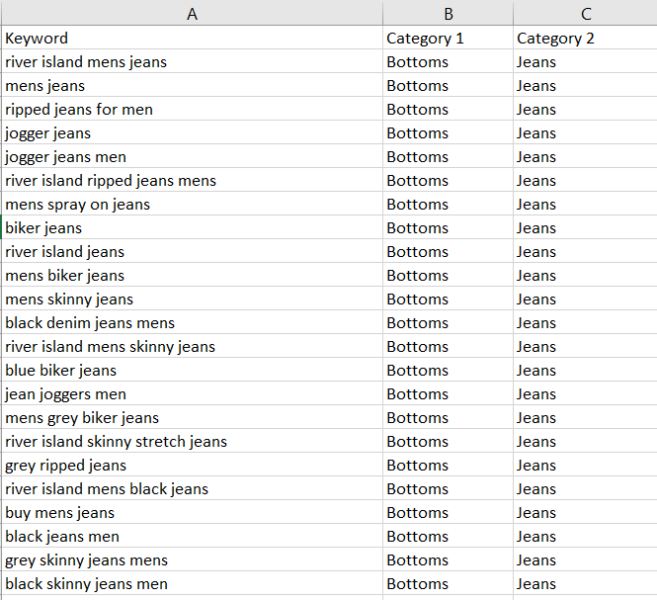
This is the start of your machine learning “training data”. There’s probably enough data here already, but I like to be thorough so I’m also going to grab all the keywords from a company I know ranks highly for every clothing based keyword – ASOS.
I’m going to repeat the process for their jeans page:

After I’ve exported the resulting ranking keywords from SEMRush, added them to my spreadsheet, dropped the categories down and de-duped the list I’ve got 1,300 keywords for Bottoms > Jeans.
I’m going to repeat the process for:
Bottoms > Trousers and Chinos
Tops > Coats and Jackets
Tops > T-Shirts and Vests
For these 3, I didn’t bother putting the River Island domain into SEMRush as ASOS ranked for so many keywords there will be enough data for my training model.
After a quick find and replace to get rid of branded keywords:

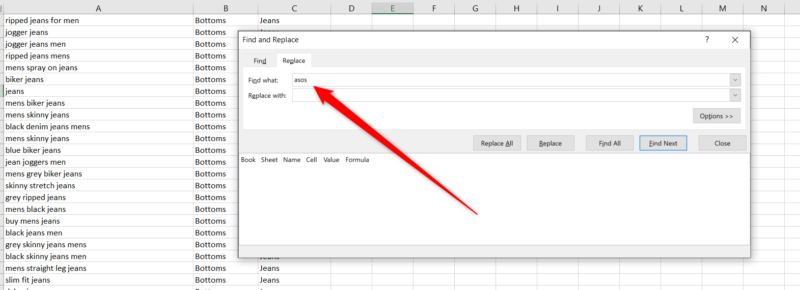
And a de-duplication, I’m left with nearly 8,000 keywords that are categorized into “Bottoms” and “Tops” at the first level, and “Jeans” and “Trousers/Chinos” at a secondary level.
Tip – you may need to use the trim function to get rid of any whitespace after the find and replace as otherwise this sheet will upload with errors when we use it as our training data:


Time spent so far: 5 minutes
You’d of course carry on doing this for all River Islands products and into as many categories as required. If you were doing men’s and women’s, they’d likely be the first category. You’d then possibly have a fourth category which breaks things like “jackets” up further into items like “puffer jackets” and “leather jackets”.
If you’re struggling to visualize the categories you may need, I will shortly be writing a post on that too. Sometimes it’s just common sense, but there is also a machine learning program to help with that too if you need it:

Step 2 – Training your machine learning model
Cool – we have our list of 8,000 unbranded keywords that have been categorized in 5 minutes.
Save the file as a CSV and then head to BigML and get registered. It’s free.
Now we’ll go through the following, incredibly simple steps, to train the machine learning program in categorizing keywords.
- Head to the sources tab and upload your training data:


- Once it’s loaded, click the file to open up the settings:

- Click the “configure data source” and ensure the categories are set to “categorical”:

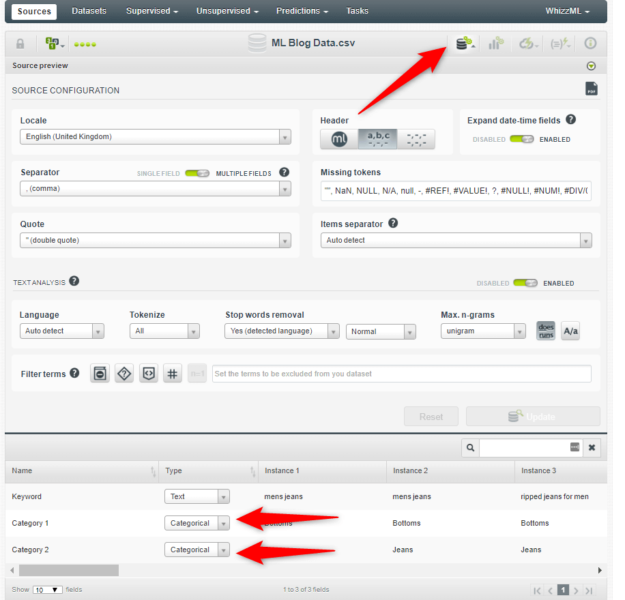
In most instances, the rest of the settings should be fine. If you’d like to learn more about what all the settings do, I’d recommend you watch BigML’s educational youtube channel here.
- Close the “configure source” settings and click the “configure data set” button. Then deselect “category 2”:


Click the “create dataset” button:


Although, before you do, rename the “dataset name” to something like ML Blog Data (Category 1).
- Select your new data set in the “data sets” tab:



After it’s finished computing, you’ll see a decision tree like this:


Again, I’m not going to go into everything you can do with this, but what it’s essentially done is created a series of if statements based on the data you’ve given it which it will use to work out the probability of a category.
For example, the circle I’ve hovered over in the image is a decision path with the following attributes – if the keyword does not contain “jeans” or “trousers”, it’s likely to be a “top” with a confidence score of 85.71%.
You can actually create something called an “ensemble model” which will be even more accurate. You’re also able to split the data and run a controlled test on it so you can see how accurate it’s going to be before you use it. If you’d like to learn more on this, reach out to me or read the documentation on the site.
So, we’ve created a model for categorizing the keywords in category one. We now need to do the same for the second category.
Head back to your sources and select your training dataset again:


Repeat the steps above, but this time deselect “category 1” when you are configuring your dataset:

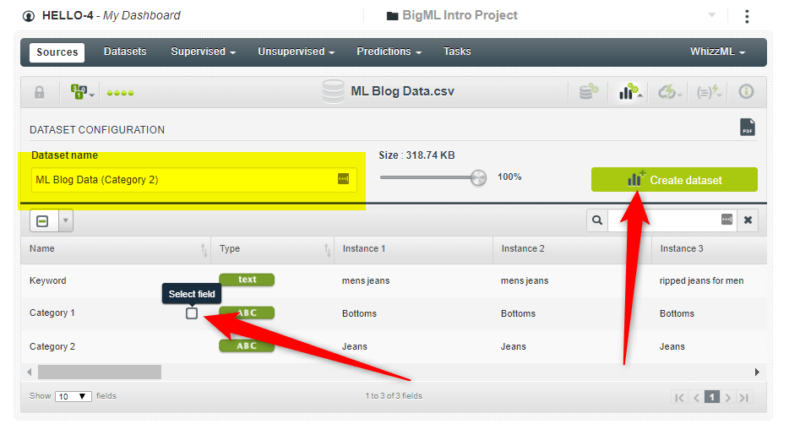
As with before, create a one-click supervised model:


Voila – your second decision tree:


So now we have 2 trained models that will categorize your keywords using machine learning with a fairly high degree of accuracy.
Time spent so far: 10 minutes (maybe an hour if you did every product category on River Islands website)
Getting the rest of your keywords
We only trained a model to cover 2 categories and 4 subcategories. Assuming you trained it for every product on the River Island’s website (which will likely take you an hour or two max. Maybe even get a Virtual Assistant to do it for you and put your feet up), the rest of your keyword research is going to be so easy.
All I’m going to do now is plug the following competitor domains into SEMRush at domain level and export their whole site’s ranking keywords (to clarify, I’m not going to be going into each product folder as I did with the training data):
https://www.superdry.com/
https://www.topman.com/
https://www.ralphlauren.co.uk/
https://www.burton.co.uk/
And I could keep going.
After I’ve deduped all the keywords on these sites and got rid of branded keywords I’m left with around 100k, uncategorized keywords.
I may also employ some standard keyword research techniques such as using merge words and keyword planner or Ahrefs keyword explorer to get even more keyword suggestions. The beauty is, we don’t have to spend ages making sure the keywords we are exporting are being categorized correctly. We can literally just plug in domains and seed keywords and export.
You’re then going to dump this huge, ugly, uncategorized list into Google sheets:


Time spent so far: 25 minutes (or an hour and 25 minutes if you got every product category from River Islands website)
Using BigML’s API to categorize your keywords
Get the BigML addon on Google sheets:
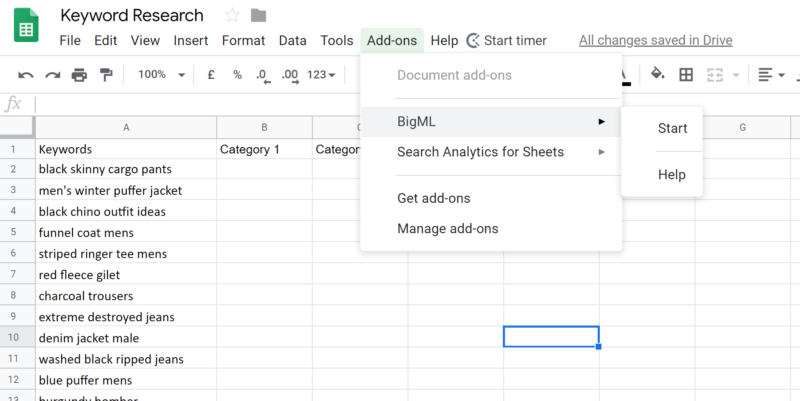
You’ll need to pop your username and API key in, but you’ll find these easily within your BigML dashboard and settings.
Now the fun begins.
- Highlight the array that needs to be categorized and select the model you trained that you want to use. In this instance I am using category 1 (at the moment I think we can only do one category at a time. I haven’t worked out how to both which is why we trained two different models):

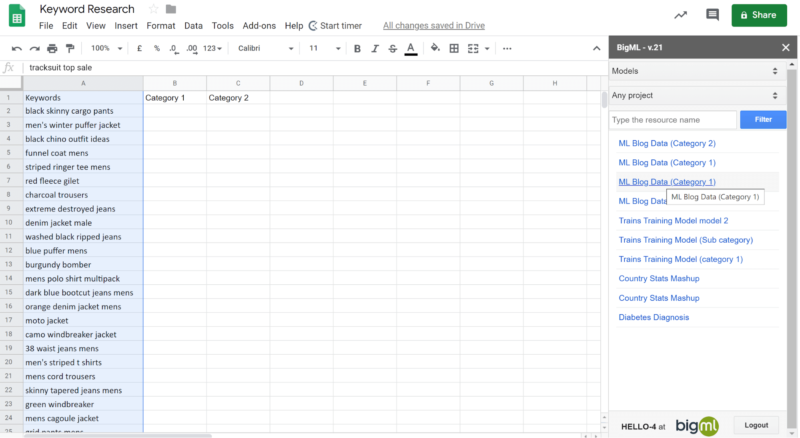
Then, click “predict” and let it go:


It may take a while depending on how many keywords you have, but at least you can get on with some other tasks. You’ll notice it also gives a probability score. I tend to just filter for anything less than 50% and delete them. I’ve got 100,000 keywords, I won’t miss the odd few.
- Next, we make a copy of the sheet, delete the two columns, and do exactly the same thing for category 2:


- Once we have both categorizations and have deleted keywords that have a low “confidence score”, you’ll just need to clear the formatting and then run a vlookup to pull them together:

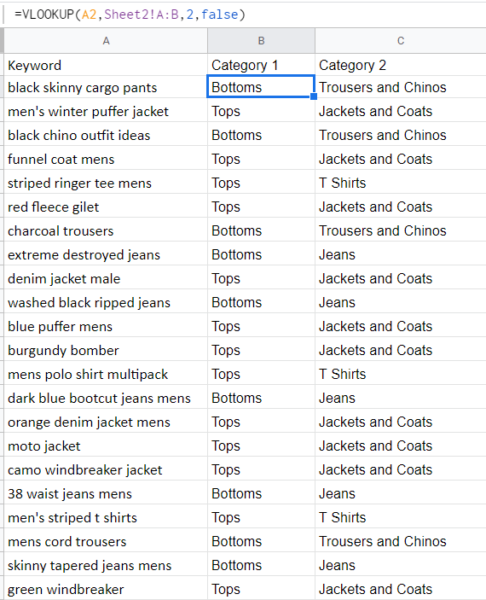
Run for as many categories as you need, and then pull in any other important data for your finalized keyword research document:

Some final notes
So there we have it – an easy way to categorize 100k keywords in less than a few hours actual working time (by that I mean you’ll have to wait for the ML to go through the keywords one by one, but you won’t be working).
- I haven’t found a way to do both at the same time yet, but I imagine there is a way to do it.
- The model we used is not as accurate as some of the other options in the engine. For example, using an ensemble model would yield better results, especially if the training model was smaller, but it’s slightly more complicated to configure.
- You can also use the engine to discover categories and closely related topics. But that’s for another post.
It’s quite basic, but surprisingly powerful and a really nice introduction to machine learning. Have fun!
The post How to use machine learning (if you can’t code) to help your keyword research appeared first on Search Engine Land.